Leave No Data Behind: A “Team All Data” Approach for Biotech

Our relationship with data has reached an unprecedented level. In addition to generating vast amounts of data, we have immersed – or perhaps even drowned – ourselves in a sea of diverse, complex, and rapidly expanding information. With this upsurge, the very nature of data in biotech – encompassing its volume, velocity, variety, veracity, and value – is also changing.
Where once manual data collection and management methods alone might have sufficed, they now fall short in the face of the sheer scale and diversity of data being produced. We need to re-evaluate traditional approaches, and stitch data from different sources – humans, equipment, and systems – into one coherent fabric of information.
We believe in a “Team All Data” approach – a strategy that is not just about collecting more data, but about capturing it in its entirety and context, thus ensuring a more complete and holistic picture of the research landscape.
In this blog post, we will outline why this approach is important and how the strategy works.
Summary Points
Upsurge of Data in Biotech: The exponential growth of data in biotech demands a re-evaluation of traditional data management approaches, emphasizing the need for integration and coherence to drive progress.
Digitalization and IoT Revolution: Digitalization and IoT enable efficient data collection, connectivity, and automation. These changes improved our ability to connect data from different sources, and are crucial for staying competitive in the industry, especially with AI/ML arriving.
The “Team All Data” Approach: Data digitalization, IoT, the human element, and AI/ML technologies underpins the “Team All Data” approach, emphasizing the value of every piece of information (“human, instrument, and system-generated data”) and paving the way for breakthroughs in science and medicine.
The Biotech Data Landscape
We can typically expect data coming from three sources in the lab:
- Human generated – manual data entries from bench scientists.
- Instrument generated – data from flow cytometers, plate readers, bioreactors, and more.
- System generated – data from QMS, LIMS, MES/LES, or pipelines and scripts, and beyond.
While human-generated data continues to play a necessary role in the lab, there is a major shift in the volume and diversity of data from equipment and system sources.
Manually transcribing data or moving data with USB drives and emails are no longer feasible or reliable. Additional handling also means more ways to introduce disconnections in data. Plus, each piece of data also comes with its metadata – the data about data – that can contribute to better insights and reproducibility.
Here is an example shared by Nathan Clark, CEO of Ganymede, of how metadata, normally overlooked, being a critical factor in a data model’s success.
The Rise of Digitalization and Digital Connectivity
A paradigm shift happened in biotech around the same time as data started growing in volume and diversity – digitalization and the advent of the Internet of Things (IoT).
Many, if not most, equipment and devices are now capable of producing digital data outputs. With this, comes new possibilities in capturing data and managing how the data flows. The introduction of IoT devices in the lab – from sensors on equipment to automated assay systems – contributes to an ever-growing stream of real-time data, some of which were once difficult to capture.
These have paved the way for more efficient data collection, greater connectivity between devices, enhanced automation in data processing. This transition is not just about adopting new technologies; it represents a major change in how research is conducted, data is managed, and discoveries are made.
Preparing for AI and ML Adoption
Data is the foundational piece for the next frontier in biotech – incorporation of artificial intelligence (AI) and machine learning (ML). These technologies offer the promise of transforming vast and complex datasets into actionable insights. However, to effectively derive value from AI and ML in biotech – whether to build your own data model, or to use other AI tools that can help provide insights, the role of data can’t be overlooked.
The journey of AI must begin with comprehensive data collection, well-defined data models, and a culture that embraces data and AI innovation – in order to avoid “garbage in, garbage out” that could significantly derail your research discoveries.
“Every [piece of data] that’s not stitched into the picture, every machine that’s not connected, every note that doesn’t make it into the data set for the AI consumption, will lower the quality of that analysis.”
Brendan McCorkle, CEO of SciNote
Importance of the Human Element
Finally, while digitally collected data is a big part of the new approach, many aspects of data collection and interpretation still rely heavily on human input. The main goal is, therefore, to design an interface that simplifies such touchpoints for better user experience and, thus, far better data collection.
It’s about creating an ecosystem where data from every source is valued and integrated.
Human-interfaced digital tools, digitally connected instruments and systems, and automated processes ensure that data collection is as comprehensive and error-free as possible. Meanwhile, AI and ML stand ready to sift through this data, providing insights and guiding future research directions.
This convergence of human experience, digitalization, and the emerging AI/ML technologies brings us to the “Team All Data” approach in biotech.
A “Team All Data” Approach – Learning from Other Industries
Before we dive into how a “Team All Data” approach would look like in biotech, let’s explore similar experiences in other industries to see how that could inform our approaches in biotech – in particular, success in sectors that are heavily, data-driven, like finance and healthcare.
Lessons from Finance
The finance industry has long grappled with the challenge of managing vast amounts of data. One key lesson here is the importance of not just collecting data but also effectively measuring and managing it.
“Most finance companies have also invested heavily in the last few decades in automation. They’ve standardized certain sets of human activity, built out decision trees, written scripts, and then tracked every speck of data possible. Today, you’d be hard pressed to find a fintech lender without an AI underwriting capability, for example.”
Nathan Clark, CEO of Ganymede
Insights from Healthcare
Similarly, the healthcare sector has made significant strides in data management, particularly in patient care and treatment.
The concept of “No Data Left Behind” is not new in healthcare; comprehensive data collection in patient health records will not only provide timely and appropriate care, but could allow for predictive analytics to resolve research and administration challenges.
For example, in 2015, UC Irvine’s Clinical Informatics Groups (CIG) migrated all of its unsearchable and unretrievable data – “multiple Excel spreadsheets and 9 million semi-structure records across 1.2 million patients” and “22 years including dictated radiology reports, pathology reports, and rounding notes” – into a single platform. These legacy records are now searchable and retrievable, and serve both UC Irvine School of Medicine for research, and the UC Irvine Medical Center for the quality of its clinical practice.
Strategies to Achieve Comprehensive Data Integration in the Lab
The “Team All Data” approach in biotechnology requires strategic efforts across the three key fronts of data collection in the lab mentioned earlier: human-generated, instrument-generated, and system-generated data.
Each of these data types plays a crucial role and demands specific strategies for effective integration and management.
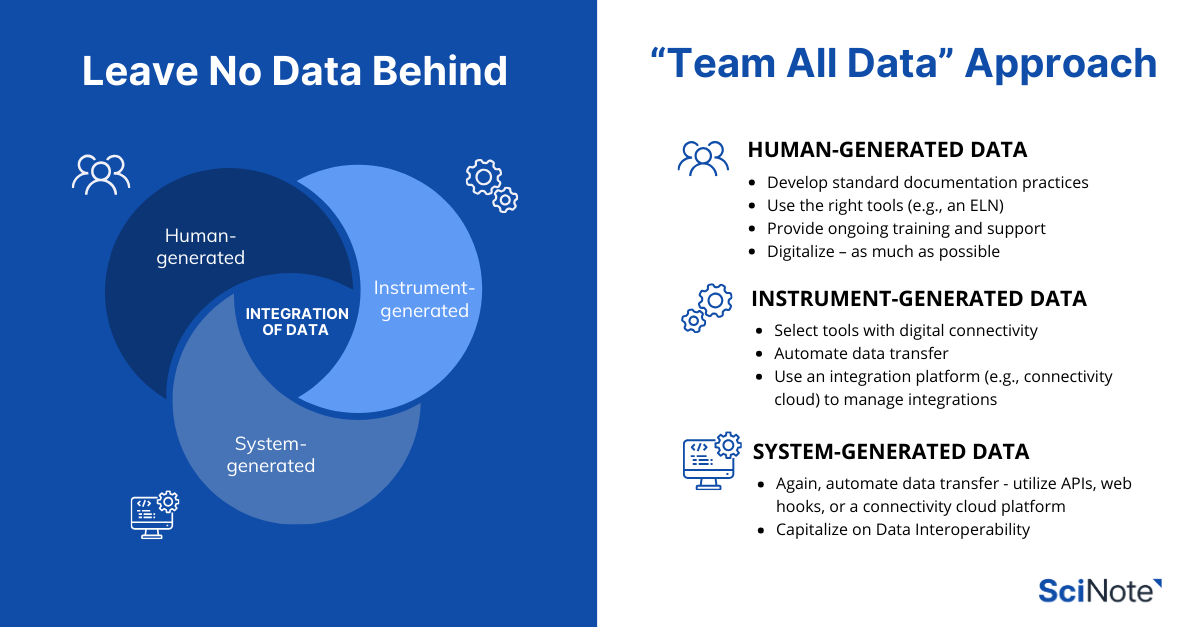
Human-Generated Data: Understanding the Human Element
Researchers and lab personnel are at the heart of human-generated data. Their observations, notes, and inputs form a significant portion of research data; any data management approach that doesn’t consider the human element will not succeed.
- Develop standard documentation practices: Implementing improved documentation practices, such as templating and efficient workflow designs, can greatly minimize errors. This ensures that data is not only accurately recorded but also consistently formatted for easier analysis.
- Use the right tools: The adoption of user-friendly interfaces, Electronic Lab Notebooks (ELNs), and ELN mobile apps that align with existing workflows is crucial. Tools that are best in class for adaptability and user experience ensure that data is captured thoroughly and accurately.
- Provide ongoing training and support: Regular training sessions and robust support systems help lab personnel stay updated on the best practices for data management, ensuring continuous improvement in data quality and consistency. Engage users in ongoing conversations on data management best practices will further improve software adoption.
- Digitalize – as much as possible: in cases where written notes or photos are necessary, digitalize them anyway (e.g., as images), and incorporate them into your digital systems such as an ELN. This at least preserves them in a digital format, and leaves possibilities for future extraction (such as OCR) and analysis.
Keep in mind that human creativity is essential in scientific research, but maintaining data structure will enhance future automation and integration. Striking a balance between the two will be a key consideration for any leaders in biotech.
Instrument-Generated Data: Leveraging Technology for Precision
Data in the lab can also come from instruments ranging from assay systems, plate readers, to flow cytometers and beyond. This data type is critical due to its precision, complexity, and volume. Migrating this data manually (e.g., data entry or moving data through USB drives or email attachments) creates an extra step where mistakes could be made, and a break in the traceability of data connecting it from its origin (equipment) and relevant metadata to where it will be stored.
- Select tools with digital connectivity: Ensuring instruments can generate data digitally is key. Another feature to look for is the Application Programming Interface (API), which allows easy access to data stored in different systems. Here are some key considerations of using API in the lab to automate data collection. It is extremely difficult to extract data from analogue devices. If data must come from equipment incapable of digital, take a photo of it and append it to your ELN.
- Automate data transfer: The ideal set up would be to connect instruments into an ELN that will serve as a data hub or dashboard; with every instrument run, the data is pushed automatically into the ELN. This mitigates the risks of manual data entry errors and preserves data lineage and metadata.
- Use an integration platform to manage integrations: Connecting instruments with ELNs using platforms that facilitate direct data transfer (e.g., connectivity cloud), such as Ganymede, can streamline this process significantly, allowing the management of various instruments to be centrally handled in a single environment.
Here is an example of directing data from a flow cytometer to an ELN (SciNote) through a connectivity cloud platform (Ganymede). Given the flexibility of Ganymede’s connectivity cloud, the possibilities of instrument to ELN connections are endless.
System-Generated Data: Harnessing Opportunities
Data generated by online platforms and other software is increasingly becoming integral to biotech research. Often, this involves connecting an ELN to Laboratory Information Management Systems (LIMS), ERP systems, pipelines and scripts, data warehouses, and more. The integration of these systems ensures a seamless flow of data across the research pipeline.
- Again, automate data transfer! Utilizing APIs and web hooks for digital connectivity can simplify data transfer, prevent errors, and ensure overall data integrity. Using a connectivity cloud platform can further support data automation, and make data integration much easier to manage.
- Capitalize on data interoperability: Ensure that different systems can communicate and exchange data. This interoperability allows for a more comprehensive view of the research landscape, where decisions are informed by a complete set of data. To this end, ensure platforms with APIs not only provide APIs, but also have well-structured end points and maintain their API regularly.
For Breakthroughs in Biotech – Leave No Data Behind
As we conclude our exploration of data integration strategies and lessons learned from other industries, it’s clear that the fusion of human expertise, technological advancements, and a holistic approach to data management is essential in moving biotech forward.
Here’s the final breakdown of the reasons behind the ‘Team All Data’ philosophy, and how to achieve it.
Bridging the Gap between Data
- Manual data collection and management methods alone are no longer sufficient due to the sheer volume and diversity of data.
- Data from different sources (from humans, instruments, and systems) often exist in isolation or depend on manual transfer; gaps in data can limit our understanding, break data traceability, and slow down research progress.
- A new approach is necessary to ensure a completer and more holistic picture of the research.
Integration Matters
- Streaming all data types into a consolidated system gives a complete picture of research activities.
- It leads to deeper insights, helping to uncover new findings and innovations.
- Good data will serve as the fundamental piece of data model and prepare labs for downstream AI/ML analysis.
Tools for Integration
- Electronic Lab Notebooks (ELNs): Act as central points for storing and analyzing data from various sources.
- Integration Platforms (connectivity cloud): Manage the transfer of data from lab equipment and other systems to one central hub (e.g., your ELN).
- Together, these technologies can be effective and efficient ways to bridge gaps between different data sources.
In essence, embracing a “Team All Data” approach in biotech means valuing every piece of information. This strategy will streamline research in your lab and create an environment ready for discovery. By using the right digital tools and bringing together all types of data, research and development can advance faster and more effectively, leading us to exciting new frontiers in science and medicine.
Related articles